MAGI-1:大規模自迴歸視頻生成
高性能·輕量級·完全開源用於多模態生成和理解的 MoE 架構
什麼是 MAGI-1 AI?
MAGI-1 是由 SandAI開發的先進自迴歸視頻生成模型,通過以自迴歸方式預測視頻片段序列來生成高質量視頻。該模型經過訓練可以對視頻片段進行降噪,實現因果時序建模並支持流式生成。 MAGI-1 在圖像轉視頻(I2V)任務中表現出色,得益於多項算法創新和專用基礎設施堆棧,提供了高時序一致性和可擴展性。
MAGI-1 概述
| 特點 | 描述 |
|---|---|
| AI 工具 | MAGI-1 |
| 類別 | 自迴歸視頻生成模型 |
| 功能 | 視頻生成 |
| 生成速度 | 高效視頻生成 |
| 研究論文 | 研究論文 |
| 官方網站 | GitHub - SandAI-org/MAGI-1 |
MAGI-1 AI:模型特點
基於 Transformer 的 VAE
使用基於 Transformer 架構的變分自編碼器,提供 8 倍空間和 4 倍時間壓縮。這帶來了快速的解碼時間和具有競爭力的重建質量。
自迴歸降噪算法
逐塊生成視頻,允許同時處理最多四個塊以實現高效的視頻生成。每個塊(24 幀)都進行整體降噪,當前塊達到一定降噪水平後立即開始處理下一個塊。

擴散模型架構
基於擴散變換器構建,融入了塊因果注意力、並行注意力塊、QK-Norm 和 GQA 等創新。具有 FFN 中的三明治標準化、SwiGLU 和 Softcap 調製,以提高大規模訓練效率和穩定性。
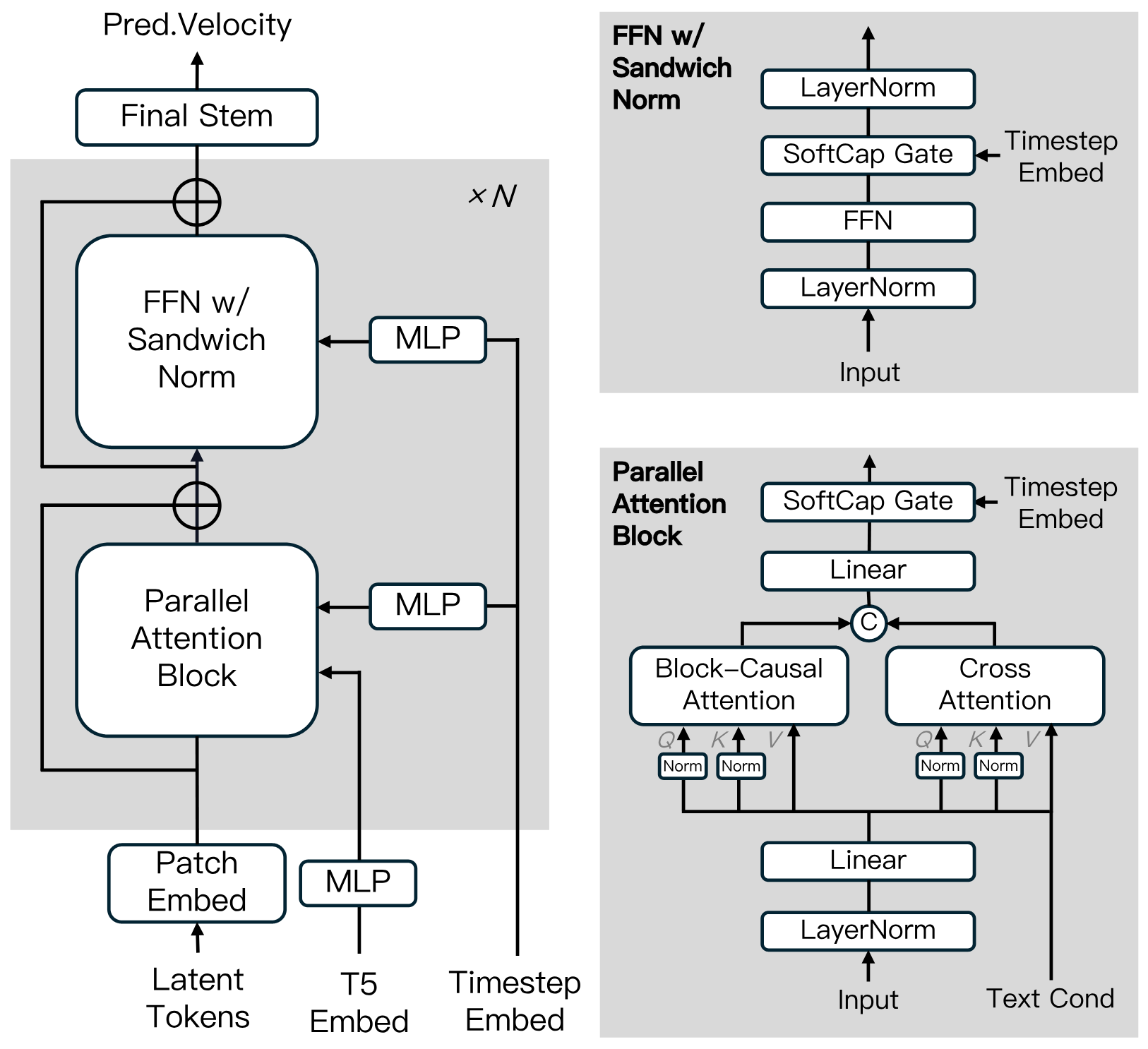
蒸餾算法
使用快捷蒸餾來訓練單個基於速度的模型,支持可變推理預算。這種方法確保了高效推理,同時保持最小的保真度損失。
MAGI-1:模型庫
我們提供 MAGI-1 的預訓練權重,包括 24B 和 4.5B 模型,以及相應的蒸餾和蒸餾+量化模型。模型權重鏈接如表所示。
| 模型 | 鏈接 | 推薦機器 |
|---|---|---|
| T5 | T5 | - |
| MAGI-1-VAE | MAGI-1-VAE | - |
| MAGI-1-24B | MAGI-1-24B | H100/H800 * 8 |
| MAGI-1-24B-distill | MAGI-1-24B-distill | H100/H800 * 8 |
| MAGI-1-24B-distill+fp8_quant | MAGI-1-24B-distill+fp8_quant | H100/H800 * 4 或 RTX 4090 * 8 |
| MAGI-1-4.5B | MAGI-1-4.5B | RTX 4090 * 1 |
MAGI-1:評估結果
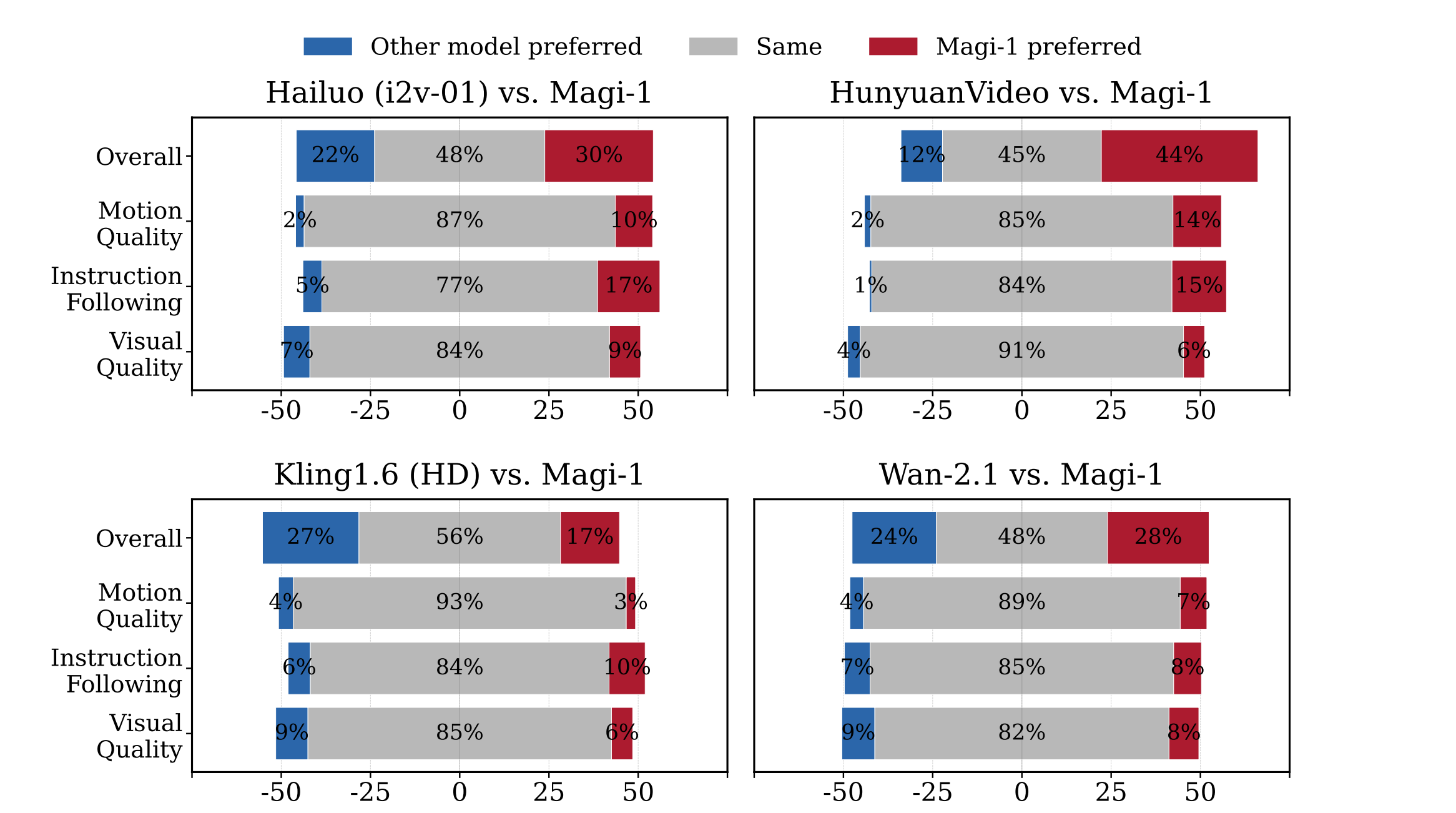
物理評估
MAGI-1 展示了 在預測物理行為方面的卓越精確性 ,通過視頻延續顯著優於現有模型。
| Model | Phys. IQ Score ↑ | Spatial IoU ↑ | Spatio Temporal ↑ | Weighted Spatial IoU ↑ | MSE ↓ |
|---|---|---|---|---|---|
| V2V Models | |||||
| Magi (V2V) | 56.02 | 0.367 | 0.270 | 0.304 | 0.005 |
| VideoPoet (V2V) | 29.50 | 0.204 | 0.164 | 0.137 | 0.010 |
| I2V Models | |||||
| Magi (I2V) | 30.23 | 0.203 | 0.151 | 0.154 | 0.012 |
| Kling1.6 (I2V) | 23.64 | 0.197 | 0.086 | 0.144 | 0.025 |
| VideoPoet (I2V) | 20.30 | 0.141 | 0.126 | 0.087 | 0.012 |
| Gen 3 (I2V) | 22.80 | 0.201 | 0.115 | 0.116 | 0.015 |
| Wan2.1 (I2V) | 20.89 | 0.153 | 0.100 | 0.112 | 0.023 |
| Sora (I2V) | 10.00 | 0.138 | 0.047 | 0.063 | 0.030 |
| GroundTruth | 100.0 | 0.678 | 0.535 | 0.577 | 0.002 |
為什麼選擇 Magi-1
體驗下一代 AI 視頻創作,在 Magi-1 中,尖端技術與開源透明性相結合。
無縫視頻生成
通過精確的幀時間調整控制您的內容,確保您的視頻符合精確的創意規格。
精確時間線控制
生成具有清晰、詳細視覺效果和流暢運動的視頻,確保專業和引人入勝的體驗。
增強的運動質量
通過我們先進的運動處理體驗逼真的運動,消除機械化的轉場,實現真正自然的視頻效果。
開源創新
加入一個透明的生態系統,所有模型和研究都可以免費獲取,促進協作改進和創新。
關於 MAGI-1 的常見問題
什麼是 MAGI-1?
MAGI-1 AI 是由 SandAI 開發的先進自迴歸視頻生成模型,通過以自迴歸方式預測視頻片段序列來生成高質量視頻。該模型經過訓練可以對視頻片段進行降噪,實現因果時序建模並支持流式生成。
MAGI-1 的主要特點是什麼?
MAGI-1 AI 視頻生成模型的特點包括基於 Transformer 的 VAE,用於快速解碼和具有競爭力的重建質量,用於高效視頻生成的自迴歸降噪算法,以及提高大規模訓練效率和穩定性的擴散模型架構。它還支持通過分塊提示進行可控生成,實現流暢的場景轉換、長期合成和精細的文本驅動控制。
MAGI-1 如何處理視頻生成?
MAGI-1 AI 逐塊生成視頻而不是整體生成。每個塊(24 幀)都進行整體降噪,當前塊達到一定降噪水平後立即開始生成下一個塊。這種流水線設計使得最多可以同時處理四個塊,實現高效的視頻生成。
MAGI-1 有哪些可用的模型變體?
MAGI-1 視頻的模型變體包括針對高保真視頻生成優化的 24B 模型和適用於資源受限環境的 4.5B 模型。還提供了蒸餾和量化模型,以實現更快的推理。
MAGI-1 在評估中表現如何?
MAGI-1 AI 在開源模型中達到了最先進的性能,在指令遵循和運動質量方面表現出色,使其成為閉源商業模型(如 Kling1.6)的強有力潛在競爭對手。它還通過視頻延續展示了在預測物理行為方面的卓越精確性,顯著優於所有現有模型。
如何運行 MAGI-1?
MAGI-1 AI 可以使用 Docker 或直接從源代碼運行。推薦使用 Docker 以便於設置。用戶可以通過修改提供的 run.sh 腳本中的參數來控制輸入和輸出。
MAGI-1 的許可證是什麼?
MAGI-1 在 Apache License 2.0 下發布。
MAGI-1 的'無限視頻擴展'功能是什麼?
MAGI-1 的'無限視頻擴展'功能允許無縫擴展視頻內容,結合'秒級時間軸控制',使用戶能夠通過逐塊提示實現場景轉換和精細編輯,滿足電影製作和講故事的需求。
MAGI-1 的自迴歸架構有什麼重要意義?
得益於自迴歸架構的自然優勢,Magi 在通過視頻延續預測物理行為方面達到了遠優於所有現有模型的精確度。
MAGI-1 的應用領域有哪些?
MAGI-1 設計用於各種應用,如內容創作、遊戲開發、電影後期製作和教育。它提供了一個強大的視頻生成工具,可以在多種場景中使用。